
robots.txt は、検索エンジンなどのクロールをこちらから制御するファイルです。
実のところ、個人運営の WordPress ブログで robots.txt を設定・作成する必要はありません。必要になるとしたら、以下の 2 パターンぐらいですね。
- 検索 bot 以外の特定のクローラーをブロックしたい
- クロールしてほしくないファイルがある
間違えて設定すると SEO に重大な悪影響を及ぼすので、十分にご注意ください。
本記事では robots.txt の基礎知識や作成方法・設定例を解説していきます。上記のパターンに該当する、またはブログ以外の大規模サイトを手掛けるときのご参考まで。
robots.txt とは
WordPress は様々なページ・ファイルを自動的に生成しており、テーマやプラグインをインストールすると、その分だけファイルも増えます。
SEO の観点で言うと、そのファイルは以下の 2 つに分けられます。
- 検索エンジンに見せるべきもの
- 検索エンジンに見せなくてよいもの
「検索エンジンに見せるかどうか」を制御するのが robots.txt の役割。
検索エンジンに見せるべき重要なページ・ファイルをこちらから指定することで、効率的にブログ内をクロールしてもらえるのです(絶対的に従ってくれるわけではない)。
この手法は「クロール最適化」と呼ばれますが、間違った設定をするとクロールをブロックすることになり、検索インデックスの登録にも影響します。
ブログ記事が Google 検索のインデックスに登録されない原因と解決策
WordPress の中身を見てみよう
robots.txt を見てみる前に、WordPress の中身がどうなっているか確認しておきましょう。
FTP クライアントソフトで接続すると、以下のように複数のディレクトリとファイルが表示されます(※ サーバーによって多少異なる)。
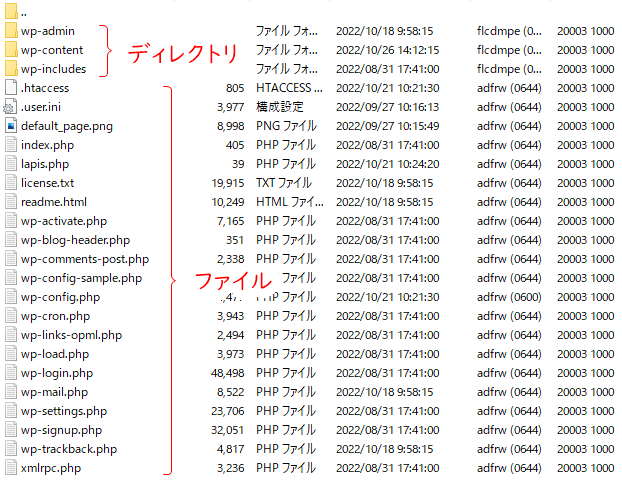
各ディレクトリ含まれているファイルは下表のとおり。
| ディレクトリ名 | 内容 |
|---|---|
| wp-admin | 管理画面の制御などに必要なファイル |
| wp-content | テーマファイル・プラグインファイル・アップロードファイル |
| wp-includes | ブログ表示に必要なファイル |
「wp-admin」の中にあるほぼすべてのファイルは管理用のため、検索 bot にクロールしてもらう必要はありません。そのため、WordPress はデフォルトで「wp-admin」内のクロールを拒否するようになっています。
なお、手動でバックアップするときやエラー修正するときは、ほぼ「wp-content」を触ることになります。いざというときのために覚えておくとよいでしょう。
WordPress の robots.txt はどこにある?
robots.txt はブラウザで実際にアクセスすると表示されます。
https://example.com/robots.txt
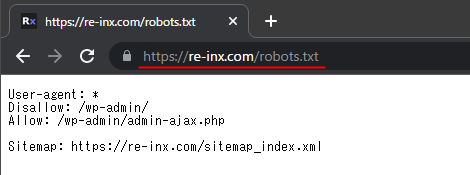
しかし、先ほど確認した WordPress のファイル群には robots.txt が見当たりません。ファイルはどこにあるのでしょうか…?
実は、WordPress は「robots.txt にアクセスがあった場合に自動生成される」仕組みになっています。実体がないので、仮想 robots.txt ということですね。
仮想 robots.txt の内容は、管理画面の設定やプラグインの設定によって自動的に変更されます。
手動で作成した robots.txt ファイルをアップロードすることもできますが、その場合は仮想ファイルは生成されずアップロードしたファイルが優先されます。
以下の条件では仮想 robots.txt が生成されないので注意しましょう。
- パーマリンク設定が「基本」になっている場合
- サブディレクトリで WordPress を運用している場合
仮想 robots.txt の中身と意味
デフォルトで自動生成される仮想 robots.txt の中身は、このようになっています。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/wp-sitemap.xmlそれぞれの意味は下表のとおり。
| 行数 | 指定 | 意味 |
|---|---|---|
| 1 | User-agent | クロール bot の種類を指定します。「*」は、すべての bot を対象とする、という意味。 |
| 2 | Disallow | 許可しない、という意味。「wp-admin」内のクロールを拒否する指定です。 |
| 3 | Allow | 許可する、という意味。「wp-admin 内の admin-ajax.php」のクロールを許可する指定になっています。 |
| 4 | Sitemap | XML サイトマップの場所を伝えています。 |
個人ブログであればデフォルトのままで問題なく、編集したから SEO で優位になることもありません。こういう仕組みがあるんだ、と覚えておけば十分です。
個人ブログで robots.txt 設定が不要な理由
robots.txt によるクロール制御が必要なのは、何万ページもあるような大規模サイトのみ。数百記事ほどの個人ブログなら、robots.txt がなくても問題なくクロールしてくれます。
ただ、管理ファイルをクロールさせるのはセキュリティの面で好ましくないので、デフォルト設定のように「wp-admin」内のクロール拒否は必要です。
一昔前は Google の性能が今ほどよくなかったため、JavaScript や CSS をクロールしないよう制御していたブログもありましたね。現在の検索エンジンは、人間と同じ見た目でページを理解しているので、CSS などのクロールをブロックすると検索順位に悪影響を及ぼしてしまいます。
別々のファイルにある JavaScript や CSS などのリソースが(robots.txt などにより)Googlebot をブロックしている場合、Google のインデクシング システムは、そのサイトを一般ユーザーと同様には認識できません。皆様のコンテンツをインデックス登録できるように JavaScript や CSS の取得を Googlebot に許可することをおすすめします。これは、モバイル向けのウェブサイトでは特に重要です。
ウェブページをより深く理解するようになりました | Google 検索セントラル ブログ
「JavaScript や CSS のクロールをブロックする」というようなノウハウは古いものなので、ご注意ください。
Googleがどのように理解しているかを知る方法
Google がページをどのように見ているのか、Search Console の「URL 検査」から確認できます。
「クロール済みのページを表示」をクリックし、「スクリーンショット」-「公開 URL をテスト」をクリック。
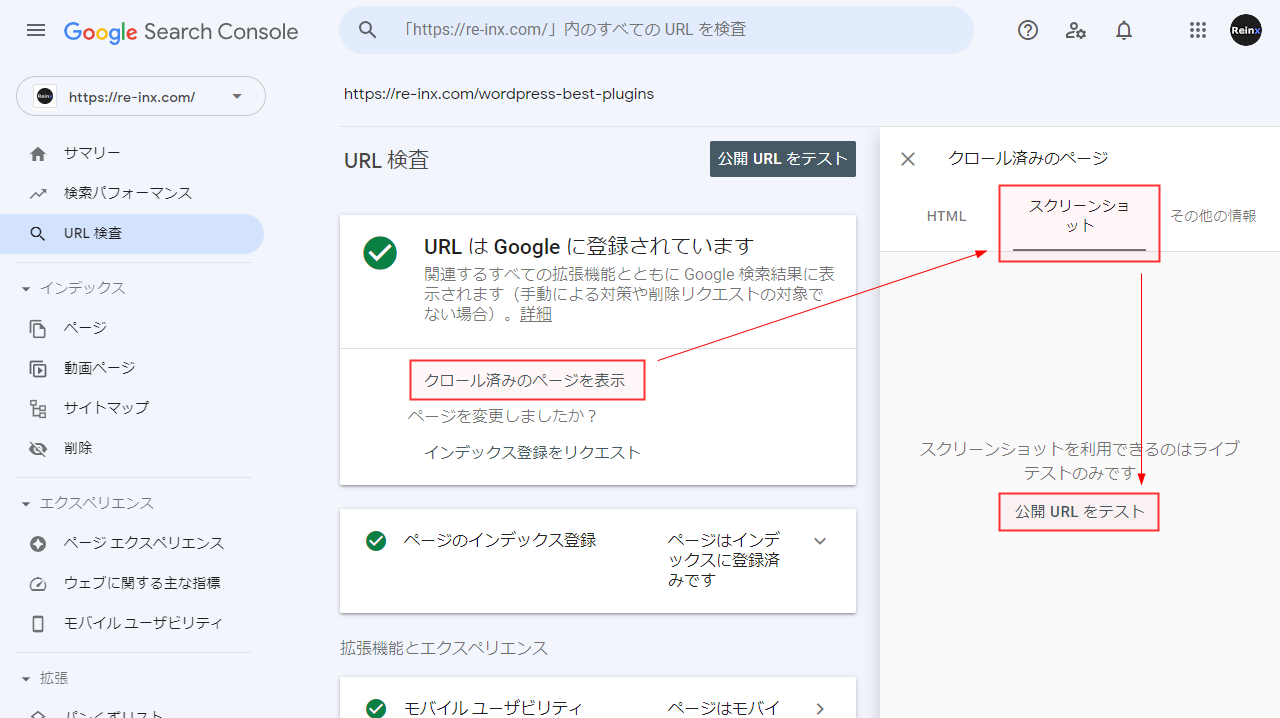
以下のように、人が見るのと同じ表示になっていれば問題ありません。
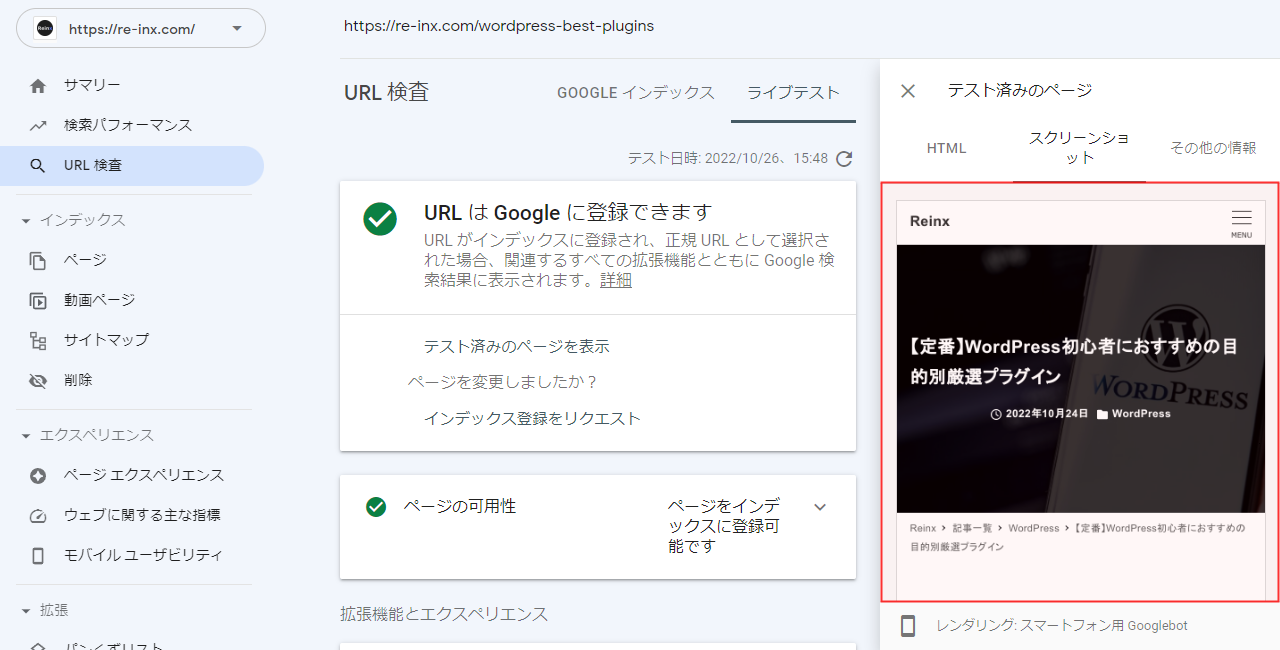
Search Console に登録していない場合は、モバイルフレンドリーテストツール でもチェックできます。
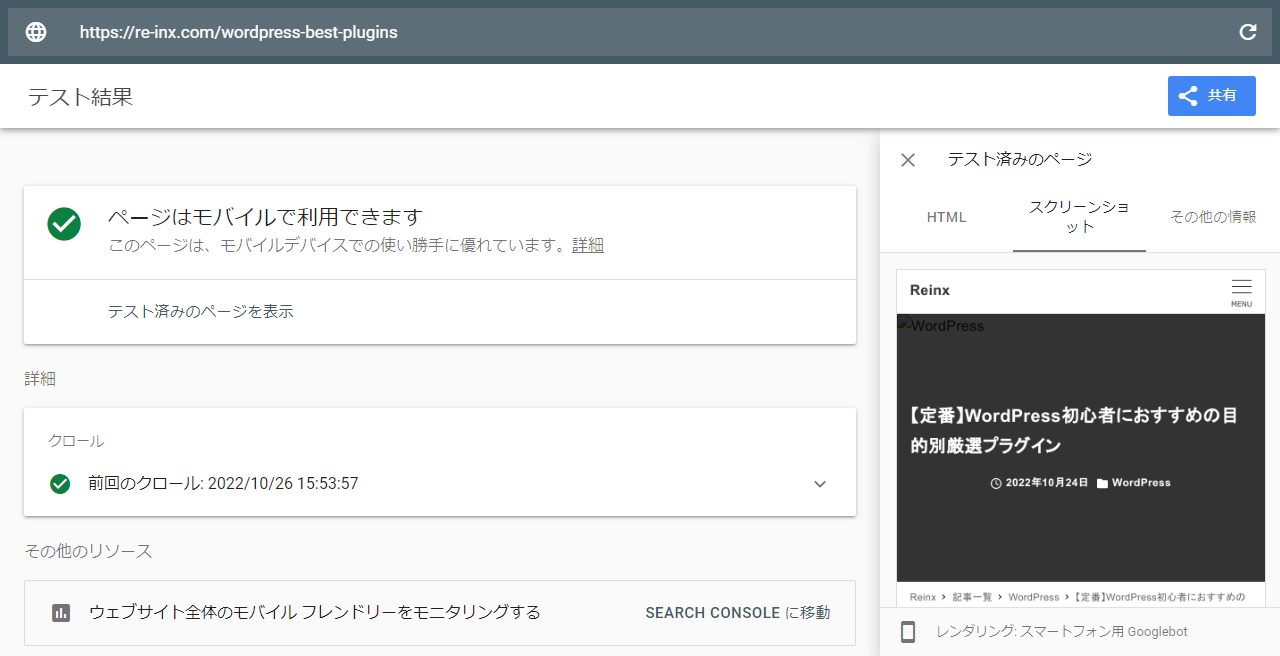
見た目が崩れている場合は、robots.txt の記述が間違っているか、一時的なエラーが考えられます。
robots.txt を触った記憶がなければ、一時的に Google がうまく処理できなかっただけなので、とくに気にしなくて OK です(表示速度が遅すぎる、という可能性もあります)。
robots.txt 作成・編集方法
robots.txt を作成・編集する方法は 2 つ。
- プラグインで仮想 robots.txt を編集する
- 実ファイルを作成して FTP でアップロードする
プラグイン利用のほうが簡単ですが、プラグインを増やしたくない場合は FTP を使いましょう。
プラグインで仮想 robots.txt を編集する場合
WordPress には、仮想 robots.txt 編集のみを目的としたプラグインがいくつかあります。
SEO 総合プラグインにも編集機能がありますが、robots.txt 編集のためだけに導入するのはおすすめしません。
サイトの状況に合わせて選択してください。
操作は簡単ですが、プラグインを外すと元に戻ってしまうのがデメリットですね。
実ファイルを作成して FTP でアップロードする場合
robots.txt を手動で作成してアップロードする場合、「テキストエディタ」と「FTP クライアントソフト」が必要です。
テキストエディタで robots.txt を作成します。ファイル名が間違っていると認識されないので気をつけましょう。「s」が抜けているケースをよく見かけます。
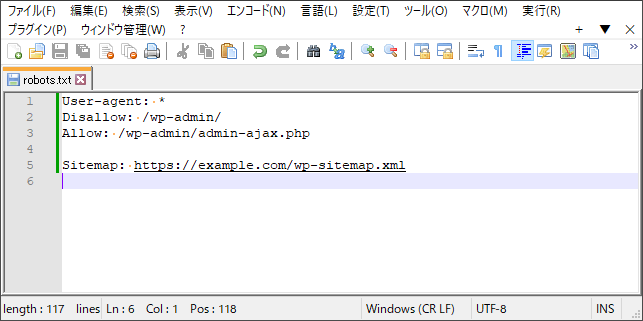
文字コードは WordPress と同じ「UTF-8(BOM なし)」で大丈夫です。
FTP でルートに robots.txt をアップロードします。
再編集する場合は、FTP で robots.txt をダウンロードして編集し、再度アップロードしましょう。
robots.txt テスターで最終チェックする
上記いずれかの方法で編集したあと、間違った設定になっていないか Search Console の robots.txt テスター でチェックしておくのが確実です。
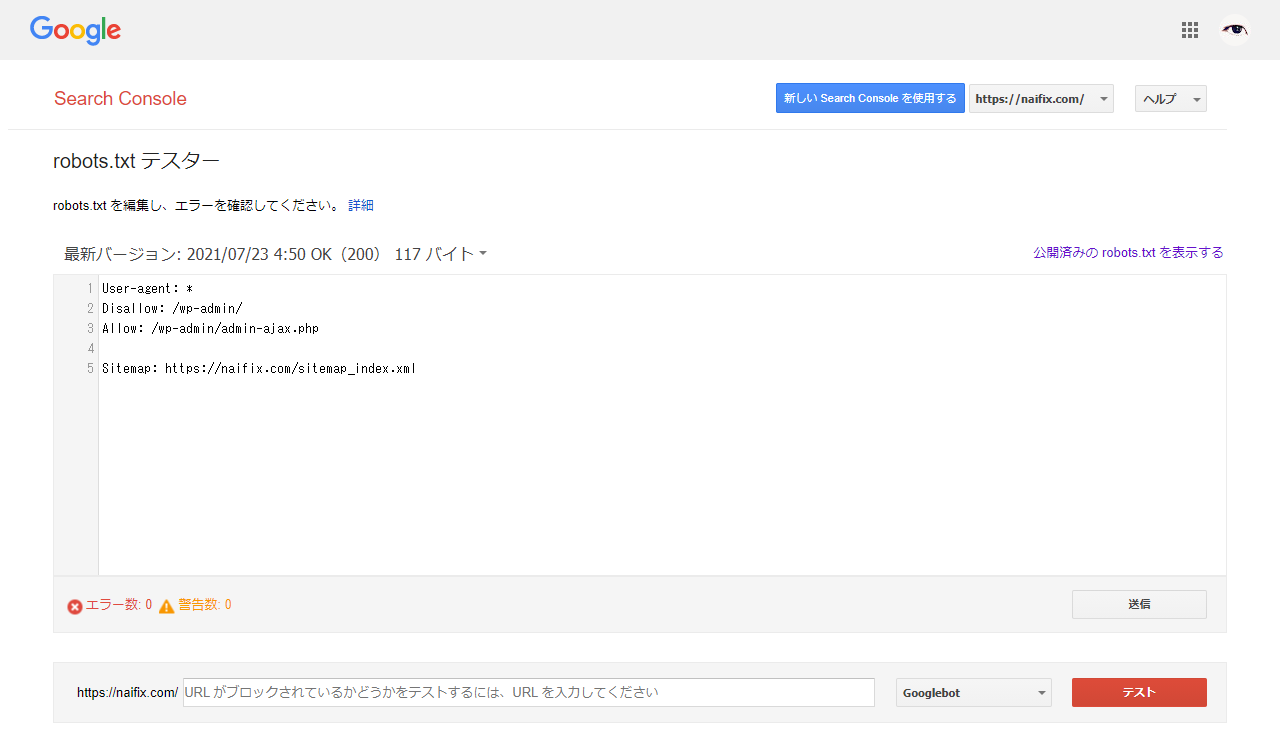
設定を間違えると、永遠に検索結果に出てこなくなる可能性もあるので、気をつけてくださいね。
2023 年 12 月 12 日に robots.txt テスターは廃止され、Search Console のレポートで確認する仕様となりました。
WordPress の robots.txt 設定例
冒頭で触れたように、個人ブログで robots.txt 設定が必要なのは以下のケースです。
- 検索 bot 以外の特定のクローラーをブロックしたい
- クロールしてほしくないファイルがある
具体的な設定例を見ていきましょう。
基本形は、WordPress の仮想 robots.txt と同じ。新たに設定する場合はここに追記していきます。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/wp-sitemap.xmlSEO ツールのクロールをブロックする場合
Web サイトをクロールしているのは、Google や Bing などの検索サイトだけではありません。
たとえば、Ahrefs や Semrush といった SEO ツールも、独自のクローラーで各ページの構成・サイトの内部構造・被リンク状況などを収集しています。そうしたデータをできるだけ見られたくないなら、クロールを拒否しておきましょう。
設定例は以下のとおり。「AhrefsBot」と「SemrushBot」のクロールを全面拒否する形です。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
User-agent: AhrefsBot
Disallow: /
User-agent: SemrushBot
Disallow: /
Sitemap: https://example.com/wp-sitemap.xml自分のブログを監査する目的で SEO ツールを利用している場合は、クロール拒否すると正確なデータが得られません。
ChatGPT のクロールをブロックする場合
AI ツールも、独自のクローラーを使って Web サイトのデータを収集し、学習に使っています。また、ChatGPT のプラグインを使い、検索上位サイトのデータを分析・リライトするような人もいます。
学習や分析を拒否したい場合は、クロールをブロックしておきましょう。User-agent は次の 2 種類です。
- ChatGPT 本体:GPTBot
- ChatGPT プラグイン:ChatGPT-User
どちらも完全に拒否する場合は、以下の設定となります。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
Sitemap: https://example.com/wp-sitemap.xml特典配布用の PDF などをブロックする場合
メルマガ登録特典など、何らかの条件をもとにダウンロードファイルを提供している場合、そのファイルが検索結果に表示されるのは好ましくありません。
たとえば「download」ディレクトリの中に PDF ファイルを入れているなら、そのディレクトリを丸ごと拒否しておくとよいですね。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /download/
Sitemap: https://example.com/wp-sitemap.xmlこのほか、XML サイトマップや他サイトからのリンクをたどって発見されることもあるので、非公開ファイルの取り扱いには気をつけましょう。
すでに検索インデックスに登録されている場合は、robots.txt ではなく .htaccess で noindex を指定します。クロールを拒否すると noindex が伝わらないので要注意。
<FilesMatch ".pdf$">
Header set X-Robots-Tag "noindex"
</FilesMatch>設定ミスによるトラブルの実例
SEO 界の権威である辻氏が、robots.txt の設定ミスに関して X(Twitter) で実例を紹介していました。
設定を誤るとどのような症状になるのか、どこが間違っているのか参考になるので、ぜひチェックしておきましょう。
よくあるrobots.txtの誤りで、致命的なトラブルになる事もあるのにあまり知られていない仕様の紹介で連ツイート。
— 辻正浩 | Masahiro Tsuji (@tsuj) October 29, 2022
誤りは表に出ることが少ないので日本語で実例紹介を見たことが無いのですが、公共の面も持つサイトでの誤りを発見したので注意喚起意図で実例を紹介します。(続く
robots.txt まとめ
個人ブログで robots.txt を作成する必要はありませんが、もし編集するならミスのないよう細心の注意を払ってください。
「これをやれば順位が上がる」という根拠のないノウハウを信じて設定しても意味はないので、それ以外の理由がなければさわらないほうがよいです。
robots.txt はだれでも見られますから、大手サイト・有名サイトのファイルをチェックしてみるのも面白いかもしれません。たとえば Google はいろいろ制御していますが、Yahoo! Japan はまったく制御していなかったりします。
SEO はいろいろ勉強することがあるので、少しずつ習得していきましょう。

